Coach AI
The five traditional positions on the basketball court are:
the Point Guard (PG), Shooting Guard (SG), Small Forward (SF), Power Forward (PF), and Center (C).
Players knew the roles of their positions and stuck to them.
After bringing in data science and analytics, coaching stragies have changed. Players that previously would play in the mid-range are now shooting primarily shots close to the basket or three-pointers.

My first task is to use unsupervised models to recluster players based on their current style of play,
rather than their traditionally defined positions.
I then begin to explore whether or not coaching strategies are optimal by building using
reinforcement learning and building a simplified basketball environment for AI agents to discover strategies.
In order to do so I will focus on a halfcourt game, 2 versus 2, and use probabilities to determine
the success of an action. For example, whether or not a player makes a shot attempt will be determined by
sampling from that player's shooting percentage distribution.
KMeans Clusters
Originally I had planned to use DBSCAN to let the algorithm determine the new number of "positions" of player types. However, all the players were being clustered together. I then chose to use KMeans with 5 clusters, one per person on the court for each team:

Examples of players in cluster 4 include: Kevon Looney, Kenyon Martin Jr. and Onyeka Okongwu.
Examples of players in cluster 3 include: R.J. Hampton, Issac Bonga, and Quinn Cook.
Examples of players in cluster 2 include: Zion Williamson, Domantas Sabonis, and DeAndre Jordan.
Examples of players in cluster 1 include: De'Aaron Fox, LeBron James, and Chris Paul.
Examples of players in cluster 0 include: Buddy Hield, Duncan Robinson, and Kelly Oubre Jr.
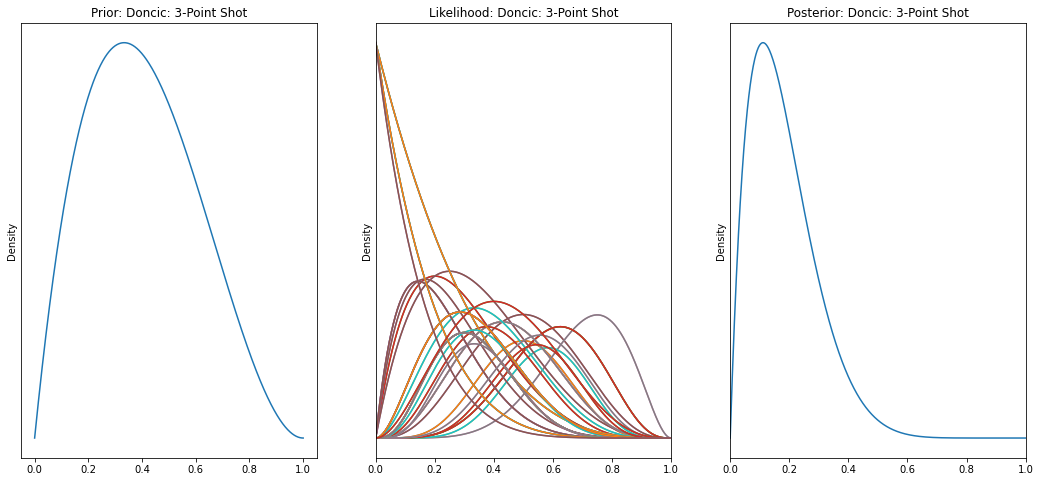
Shot Distributions
I then established prior distributions for shooting percentages and iterated through each game to
update and create posterior distributions for player shooting percentages.
I focused on two up and coming teams and their young star players, Julius Randle and JR Barrett
from the New York Knicks and Luka Doncic and Kristaps Porzingis from the Dallas Mavericks.
Environment, Player & Agent Modeling
In the Player class I brought in the shot distributions and created attributes such as whether or not a player has the ball or is defended.
I also created the Environment class that established the court and the rules, actions that an agent can take, and rewards for the actions.
Baseline
I ran agents that took random actions in order to establish that the model was functioning and to test to see that the environment and its rules weren't too easy or too difficult to solve.
Q-Learning
After establishing the random agent model as the baseline I then ran a Q-Learning model for the agents to learn the best policy. After running 250,000 trials the following shot chart was produced from the q-table.

If you would like to learn more about my process and see the full project and code please visit the following Github link.

